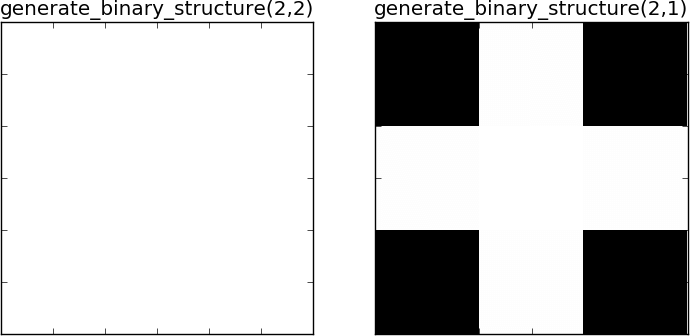
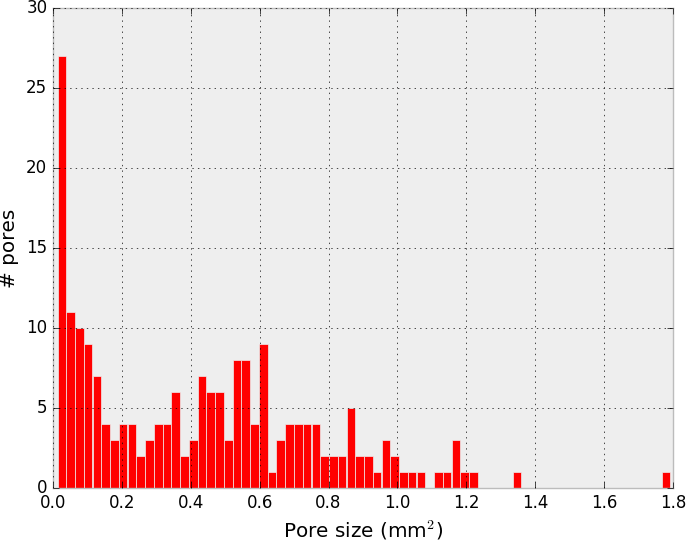
Have you got a tomographic volume reconstruction of a porous sample and want to quantify the porosity? Interested in the statistical analysis of the pore distribution of your sample? Let’s look at some quantitative ways to characterise the properties of your sample with Python.
We start from the volume data of our porous sample and we segment it, so to produce a binary volume where the pores will be labelled as ‘1’ and the rest will be labelled as ‘0’.
There are many ways to segment your data using thresholding or other methods. You can read few excellent examples here or here.
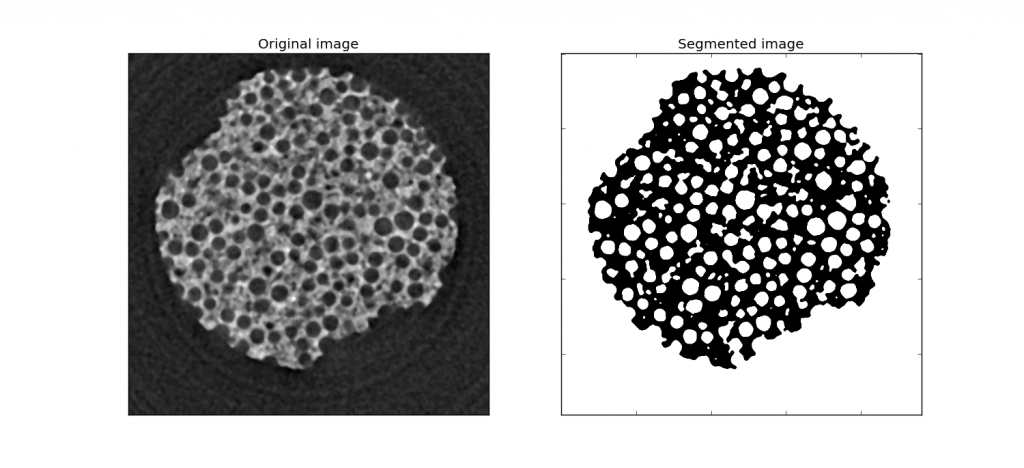
OK, here’s my example of the virtual slice of a porous material and the corresponding segmented slice. Note that we are going to work on a single slice (2D array), but the method can easily be extended to a 3D array.